
Data
Grasping how data is managed is crucial for effectively utilizing your Flows.
Data flow is broadly classified into two types:
Input data comprises a variable name and its associated list of content. For Outputs, the generated data is structured in a specific format, as explained below.
You should be acquainted with the various node types in your flow, as detailed earlier in the Flow section of this documentation. This section delves deeper into how each node type processes data.
Inputs
Input Modes
There are typically two modes available when setting up an Input:
- Input Variable

- Source

As an Input Variable, it constructs queries based on the input's values (illustrated in the upcoming example).
In Source mode, the input is treated as a singular value.
Please note that in certain scenarios, such as when a Newsroom Node is connected to a Question Node, this option may automatically switch to Input Variable mode.
Input Structure
An input consistently comprises:
- Variable Name (key)
- Content (values)
The variable name is used in your queries (Questions) as a reference while cycling through the values. For
instance, in Input Variable mode:
Consider a fruit list where your variable name is fruit, with values like apple and kiwi.
In your query, you can reference {fruit}. During execution, {fruit} will be substituted with the current
fruit. So, if your query is:
Is it safe for my dog to eat this fruit: {fruit}?
It will generate two distinct queries:
Is it safe for my dog to eat this fruit: apple?
Is it safe for my dog to eat this fruit: kiwi?
Combining Multiple Inputs
You can combine multiple inputs together to generate more complex queries. To mix these inputs you have to indicate how we should generate the requested queries.

In your Question node, you can select from two input mix modes:
- Linear Mode
- Product Mode (Cartesian Product)
Imagine the following inputs in Input variable mode:
First Input:
vehicle
car
bus
Second Input:
speed
slow
fast
With the query:
Can you tell me if a {vehicle} is {speed}?
In Linear Mode, the queries will be:
Can you tell me if a car is slow?
Can you tell me if a bus is fast?
In Product Mode, a full combination will result in more queries:
Can you tell me if a car is slow?
Can you tell me if a car is fast?
Can you tell me if a bus is slow?
Can you tell me if a bus is fast?
Empty values
First Input:
day
monday
tuesday
thursday
Second Input:
month
january
april
Notice that in the third value, the day and month variables lack values. Consequently, the queries generated for this example will be as follows:
| day | month |
|---|---|
| monday | january |
| tuesday | |
| thursday | april |
Source Mode
Let's delve into the Source mode introduced earlier. Similar to the Input variable mode, you'll use a
specific key. This key retrieves your input's content within your query. Consider this example:
Imagine your input is:
key:
source
value:
An old silent pond
A frog jumps into the pond—
Splash! Silence again.
Now, formulate a query:
Can you make a poem with 200 words based on this haiku: {source}
This will demonstrate the mode's behavior, substituting {source} in the query with the input's value.
It's particularly beneficial for tasks like translation.
A unique aspect of Source mode is that the source remains constant and is available across all generated queries.
Input Nodes
Various Nodes are available for feeding inputs into your Questions:
- Local List
- Text
- Input File
- API URL
- Web Browser
- Previous Question Response
Local List Node
The Local List is the most straightforward, directly supplying your Question with a content list and a variable name.
Text Node
You can use raw text to feed your Question with a variable name.
Input File and API URL Node
Input File and Input URL follow the same pattern. The file type you use dictates the structure required to prevent undesired outcomes:
API URL Processing Modes
For API URL nodes specifically, you can choose between two processing modes:
Default Mode: The JSON structure is used directly as variables. This is the standard behavior where your JSON should already be in the expected variable format.
Advanced Mode: Uses JMESPath expressions to transform complex JSON responses into simple variable arrays. This is perfect for APIs that return nested or complex data structures.
TXT, DOC, DOCX, ODT Files
your_variable_name
value_1
value_2
...
value_n
Example:
day
monday
tuesday
wednesday
Using a query like what is the day after {day}? will result in these queries when the Flow runs:
what is the day after monday?
what is the day after tuesday?
what is the day after wednesday?
JSON Files
A correctly formatted JSON file for an Input looks like this:
{
"day": [
"monday",
"tuesday"
],
"month": [
"january",
"february"
]
}
If your question is what is the day after {day} and the month after {month} in Linear mode, the following
queries are generated:
what is the day after monday and the month after january?
what is the day after tuesday and the month after february?
Choosing Product mode (Cartesian Product) for your Question leads to these combinations:
what is the day after monday and the month after january?
what is the day after monday and the month after february?
what is the day after tuesday and the month after january?
what is the day after tuesday and the month after february?
Files or URLs are particularly user-friendly and potent for such tasks.
Advanced Mode with JMESPath
When using Advanced Mode with API URL nodes, you can transform complex JSON responses using JMESPath expressions. This is particularly useful for real-world APIs that return nested data structures.
Example: News API Response
Consider an API that returns this complex JSON structure:
{
"articles": {
"results": [
{
"uri": "123",
"title": "Climate Change Impact",
"body": "Scientists report new findings on climate change...",
"source": {
"title": "Science Daily"
}
},
{
"uri": "124",
"title": "Technology Breakthrough",
"body": "New AI model shows promising results...",
"source": {
"title": "Tech News"
}
}
]
}
}
Using the JMESPath expression:
articles.results[].{title: title, body: body, source: source.title}
This transforms the complex structure into clean variables:
[
{
"title": "Climate Change Impact",
"body": "Scientists report new findings on climate change...",
"source": "Science Daily"
},
{
"title": "Technology Breakthrough",
"body": "New AI model shows promising results...",
"source": "Tech News"
}
]
The JMESPath processing then converts this array of objects into the variable format:
{
"title": ["Climate Change Impact", "Technology Breakthrough"],
"body": ["Scientists report new findings on climate change...", "New AI model shows promising results..."],
"source": ["Science Daily", "Tech News"]
}
Now you can use {title}, {body}, and {source} variables in your Question nodes.
[
{
"key": "value",
"key2": "value2"
}, ...
]
to create multiple named variables. Any other format will either create a single {result} variable or no variables at all.
JMESPath Examples:
✅ Creates multiple variables:
articles.results[].{title: title, body: body}→ Creates{title},{body}variablesarticles.results[:2].{title: title, body: body}→ Same as above, but limits to first 2 items
❌ Creates only {result} variable:
articles.results[0].title→ Returns["Single Title"]as{result}(single scalar value)
❌ Creates no variables:
articles.results[].title→ Returns["Title 1", "Title 2"]but items are strings, not objectsarticles.results[:2].title→ Same issue - array of strings, not objectsarticles.results[0]→ Returns single object, not array of objects
Learn more about JMESPath syntax at jmespath.org
CSV Files
The separator should be auto-detected, so in most cases it should work. But in cases where auto-detection does not fit the use-case, then it can become a mess.
For this reason, we strongly recommend using a semicolon ; as the separator and avoiding quotation marks " for
text enclosure.
An ideal CSV file format for input looks like this:
day;month
monday;january
tuesday;february
XLS, XLSX, ODS Files
Your preferred spreadsheet files (XLS, XLSX, ODS) can be used as inputs. It's crucial, however, to maintain a clean file, devoid of unnecessary sheets or extraneous data. An example of a properly organized spreadsheet is as follows:
| day | month |
|---|---|
| monday | january |
| tuesday | february |
Keep in mind, a table with numerous rows will produce a significant number of queries. It's essential to manage your input data effectively.
Web Browser Node
Understanding the operation of this node is essential due to its unique data handling method. Before utilizing it, it's important to familiarize yourself with its functioning. A comprehensive description of its mechanisms, including how it processes and outputs data, is available in the Flow documentation. Please ensure you read this information thoroughly.
Newsroom Node
To learn more about the Newsroom Node, please refer to the documentation provided here.
Articles Node
To learn more about the Articles Node, please refer to the documentation provided here.
Question as an Input (Question to Question Link Node)
Leverage the AI to dynamically generate inputs and channel these into another Question. It's vital to ensure that the AI correctly formats its output.
Within your Flows, the Question Link node is necessary to link two Questions. Here's how it's done:
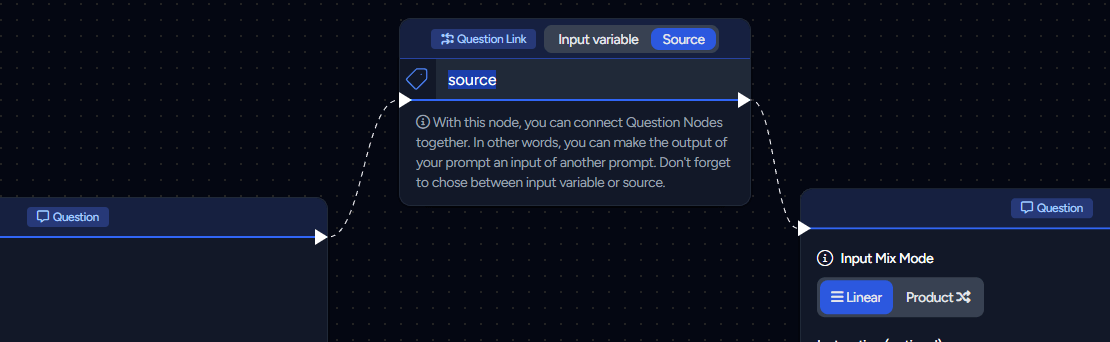
Testing the generation of dynamic inputs with an Instruction is crucial to confirm that the output aligns with the format described in this documentation. Failure to do so could lead to the consumption of unnecessary units.
For example, a functional query to create an input for another Question might be:
Give me a list of animals that live in Japan. Provide a list only, without comments.
Start with "animal" and list up to 10 animals, without numbering.
Avoid capitalization at the start of each name and exclude empty lines.
This would yield an output such as:
animal
snow monkey
japanese macaque
sika deer
japanese serow
tanuki
japanese giant salamander
pika
japanese sparrowhawk
red-crowned crane
pacific white-sided dolphin
Outputs
Outputs are arguably the most critical aspect of your Flow. With a properly configured pipeline, the results from your queries can be directed to various destinations, including:
- WordPress for articles or posts
- File storage
- API URLs
- Question Link nodes
Output Variables
Please be aware that the following variables will be available by default in the Output Nodes. Should you choose to define these variables in your Flow, your specified values will take precedence over the default ones.
| Variable | Description | Example |
|---|---|---|
{date} |
The current date (UTC) | 2024-02-04 |
{time} |
The current time in 24-hour format (UTC) | 21:48:16 |
{month} |
The current month (UTC) | February |
{year} |
The current year (UTC) | 2024 |
WordPress
Each output allows you to either create or update a post/article in WordPress. Every generated query activates a corresponding action via the WordPress API. For more information on WordPress integration with LaminarFlow, please refer to the dedicated section in the documentation.
Files and API URLs
Given that multiple queries are possible, the output format will vary depending on the chosen file type:
TXT, DOC, DOCX, ODT Files
Consider the following two inputs:
day
monday
tuesday
and
month
january
february
For a query such as:
What is the day after {day} and the month after {month}?
The output in your file/URL, in Linear mode, would appear as:
day=monday,month=january: The day after Monday is Tuesday, and the month after January is February.
day=tuesday,month=february: The day after Tuesday is Wednesday, and the month after February is March.
This format indicates the input used for each query preceding the :
CSV Files
In CSV format, the separator is ; and the enclosure is ":
"day";"month";"output"
"monday";"january";"The day after Monday is Tuesday. The month after January is February."
"tuesday";"february";"The day after Tuesday is Wednesday. The month after February is March."
JSON Format
The JSON output is structured as follows:
[
{
"input": {
"day": "monday",
"month": "january"
},
"output": "The day after Monday is Tuesday, and the month after January is February."
},
{
"input": {
"day": "tuesday",
"month": "february"
},
"output": "The day after Tuesday is Wednesday, and the month after February is March."
}
]
XLS, XLSX, ODS Files
For spreadsheet formats like Excel and OpenDocument, the output is organized as:
| day | month | output |
|---|---|---|
| monday | january | The day after Monday is Tuesday. The month after January is February. |
| tuesday | february | The day after Tuesday is Wednesday. The month after February is March. |
Output Question Link
When using a Question Link for output, ensure to adhere to the guidelines discussed earlier in the 'Question Link' section of the Input chapter.